噪声预测(噪声预测的无监督学习)
本文内容摘要
1、本文从informax(信息最大化)算法入手,解释如何最大程度地保留输入数据信息,进而学习最优的密集表征。
2、把表征限制在一个单位范围内,对于informax算法框架十分有利,本文阐明了其中的原因。
3、一个分布均匀的确定性表征是否存在,以及informax算法标准是否达到了最大化,问题的答案非常明显。因此,如果我们相信这样的解决方法是确实存在的,那么我们完全可以直接寻找接近均匀分布的确定性映射。
4、“噪声目标法”(NAT)就是寻找一个在单位范围的边缘是均匀分布的确定性映射。具体来说就是,从统一样本中,尽量缩小实际操作的“地球移动距离”(EMD)。
5、Bojanowski和Joulin在他们的论文中提到了随机使用“匈牙利算法”来更新分配矩阵,在本文的最后,我也对此作了简单的阐述。
通过信息最大化进行表征的学习
假设我们现在将要学习来自于一些 pX分布的数据 xn的一个密集表征。通常情况下,表征可以用一个随机变量zn表示,这个变量作经过了一些参数分布条件
的采样。
xn~pX
zn~pZ|X=xn,
在变化的自编码器中,这个参数分布条件
会被称为“编码器”或者是“识别模型”,又或者是“摊销变化后端”。不过重要的是,我们现在是跟“编码器”进行一对一工作,无需明确地指示出一个生成的分布
。
“信息最大化”原则的意思是一个好的表征的信息熵是密集分布的,同时还要保留输入X中尽可能多的信息。这一目标可以正式表达为:
表示“互信息”,
表示“申农熵”。
我还引入了下面的符号分布:
在实际中,这些“最优化问题”有可能是以各种不恰当的方式呈现的,所以这些问题本身也是存在问题的。
1、一般情况下,边缘的熵是很难估测的。我们需要采取一种比较智能的方式来限制
,不需要对熵进行实际的计算。
2、如果一个表征具有确定性和可逆性,那么“互信息”在连续的空间内就是无限循环的,而这些最优化问题就会变得毫无意义。所以,为了使这些最优化问题变得有意义,我们需要确保那些病态的可逆行为永远都不会出现。
为了解决以上问题,我们可以作以下的改变:
1、首先,运用勒贝格有限测度,把Z的定义域限制在的
子集范围内,这样一来,微分熵
在这个定义域内就会始终受到均匀分布的熵的约束。为了与论文内容一致,我们可以把表征定义域限制在欧几里得单位
的范围内。
2、第二,尝试把
和多噪声表征
(
表示噪声)之间的信息最大化。我将假定
遵循了一种球状的分布规则,而这个添加的噪声在实际操作中,从任何给定的范围
内,设定了一个
预测的上限(或者是设定了表征可逆性的上限);从而也框定了“互信息”,把它限制在一个有限值内。那么我们的最优化问题就变成了:
这个损失函数生成了一种直观的感受:你可能正以一种非常随机的方式,把你的输入Xn在单位范围内映射为Zn,但是这样做,原始数据点Xn就会很容易从Zn的噪声版——
恢复。换句话来说,我们是在寻找一个在某种程度上能够抵挡加性噪声的表征。
确定和统一的表征
我们能很轻易地指出是否存在至少一个表征pZ|X;,这个表征具备以下两种特质:
第一,Zn是Xn的确定性函数;第二,
是在单位范围内的均匀分布。
如果具备了以上特征,那么这个
就是信息最大化目标中的全局最优点。
但值得关注的是,这个确定性的表征也许并不是独一无二的,可能会存在很多很多好的表征,尤其是当
时。
再看这样的案例:假设X是一个标准的多元高斯,表征Z是X的一个正常的正交投影。例如,针对一些正交转换A来说:
Z在单位范围内将会具备均匀分布,而这也是一个确定性的映射。因此,Z是一个信息最大化的表征,它对任何同样正交映射A都十分有利。
所以,如果我们假设只存在至少一个确定的、统一Px的表征,那么寻找确定的、能够把数据映射为大致均匀分布的表征就意义非凡了。
这才是“噪声目标法”(NAT)的目的所在
为达到一个在表征空间里均匀的分布,NAT采用的方法是使“地球移动距离”(EMD)最小化。首先,我们根据已有的数据点,随机画了尽可能多的均匀分布,我们把这些均匀分布看作Cn。然后,我们试着把每个Cn与一个数据点配对,直到Cn和对应的表征
之间的“均方距离”达到最小值。一旦配对成功,已配对的表征和噪声向量之间的“均方距离”就能被视为测量分布均匀性的度量单位。确实,这是对“瓦瑟斯坦距离”(Pz分布和均匀分布之间的距离)的一种经验性估测。
信息最大化的表征就一定是好的表征吗?
过去的几天,我做了太多这种类型的讲话——什么是一个好的表征?无监督的表征学习究竟是什么意思?对于InfoMax表征,你同样可以提出这样的问题:这是找到一个好表征的最佳指导原则吗?
还不够。对于新手,你可以以任意的方式转换你的表征,只要你的转换是可逆的,百思特网那么“互信息”就应该是相同的。所以你可以在可逆的条件下对你的表征做任何转换,无需考虑InfoMax的目标。因此,InfoMax标准不能单独找到你转换过的表征。
更有可能出现的是,我们在操作经验中所看到的那些成功案例都是ConvNets与InfoMax原则联合使用的结果。我们仅在ConvNet比较容易展示的表征中,对信息进行最大化操作。
本文总结
NAT的表征学习原则可以理解为寻找InfoMax表征,即最大化地保留了输入数据的信息的有限熵的表征。在“卷积神经网络范例”中也存在类似的信息最大化的解读,它根据数据点的噪声版本来估测这个数百思特网据点的指数。在开始的时候,你肯定会认为这些算法很奇怪,甚至是超乎常理的,但是如果我们把这些算法重新理解为信息最大化工具,我们就会对他们有所改观。反正至少我对他们是有了更深的认识和理解的。
特别内容:一些关于EMD随机版本的小提示
以这种文字的方式实施EMD度量的难处在于,你需要找到一个最优的分配方案,分配好两个实操经验上的分布和尺度
。那么为了回避这个难题,作者提出了一个“最优分配矩阵”的任意更新升级,即所有的配对一次只进行一小批更新升级。
我并不指望这个“最优分配矩阵”能有多有用,但是值得一提的是,这一矩阵使这个算法很容易陷入局部的最小值。假设表征
的参数是固定的,我们变化、更新的只是其中的分配。我们来看下面图形中的解读:
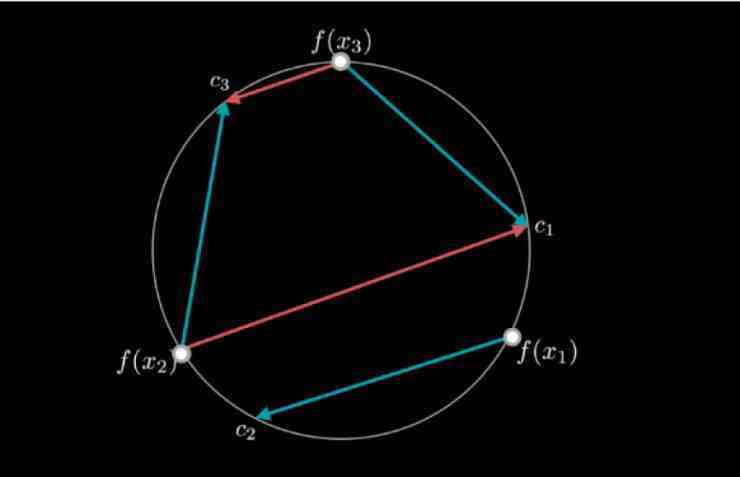
在这个2D的球状单位(圆圈)上的X1,X2,X3分别是三个数据点,这些数据点之间距离相等。是三个可能的噪声分配,三者之间也是距离相等。C1,C2,C3很明显,其中的最优分配就是把X1与C1配对,X2与C2配对,X3与C3配对。
假设,我们当前的映射是次优的,如图中蓝色箭头指示的;而且我们现在只能在尺寸2的minibatch上更新分配。在尺寸2的minibatch上,我们的分配只有两种可能性:第一,保持原来的分配不变;第二,把所有的点都互换,就像图中红色箭头指示的。在上图这个例子中,保持原来的分配(蓝色箭头)比互换所有的点(红色箭头)更可行。因此,minibatch的更新将会使minibatch算法陷入这个局部的最小值。
但是这并不意味着这个方法没有用。当
也同时被更新了的情况下,这个方法确实能让算法摆脱这个局部最小值。其次,batch的尺寸越大,就约难找到这样的局部最小值,那么算法也就越不会陷入最小值。
我们可以转换一种思维方式,把这个任意的“匈牙利算法”的局部最小值看作是一个图表。每一个节点代表一个分配矩阵状态(一个分配排列),每一条边对应一个基于minibatch的有效更新。一个局部最小值就是一个节点,这个最小值节点与其周边的N!节点相比成本较低。
如果我们把原本大小为B的minibatch扩大到一个总样本的尺寸N,那么我们就会在图中得到一个N!节点,而每个节点百思特网都会超出额度,达到
。那么任意两个节点连接的概率就是
。Batch的B尺寸越大,我们这个图表就会变得越紧密,局部最小值也就不存在了。